 26.10.2019
26.10.2019  4 409
4 409 
Как масштабировать семантическое ядро в сезон? И получить лиды по 1000 рублей с НДС
Пошаговая инструкция для всех!
Стояла задача масштабировать семантическое ядро. Как это реализовали? Ответ на этот вопрос читайте в данной статье.
Для начала определимся с нишей, которую будем использовать для примера. Пусть это будет установка пластиковых окон. Важно понимать, что сервис Wordstat выдает нам результат за предыдущие 30 дней.
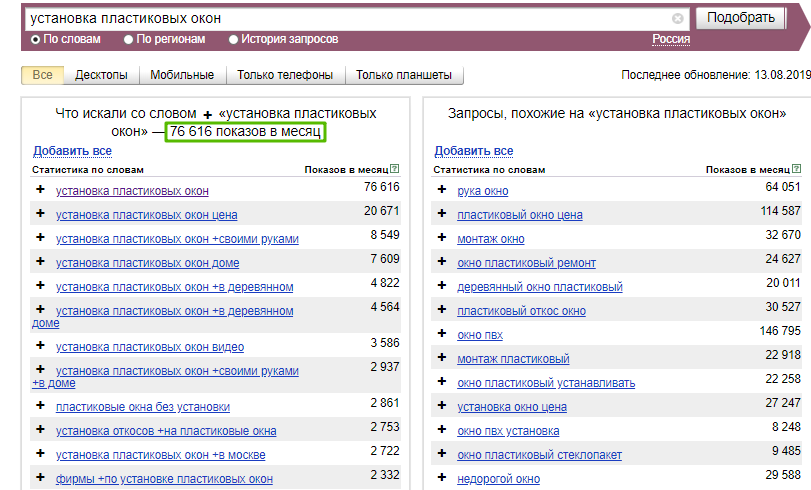
Время моего сбора семантики - середина августа и по данным за предыдущий год идет самый разгар сезона.
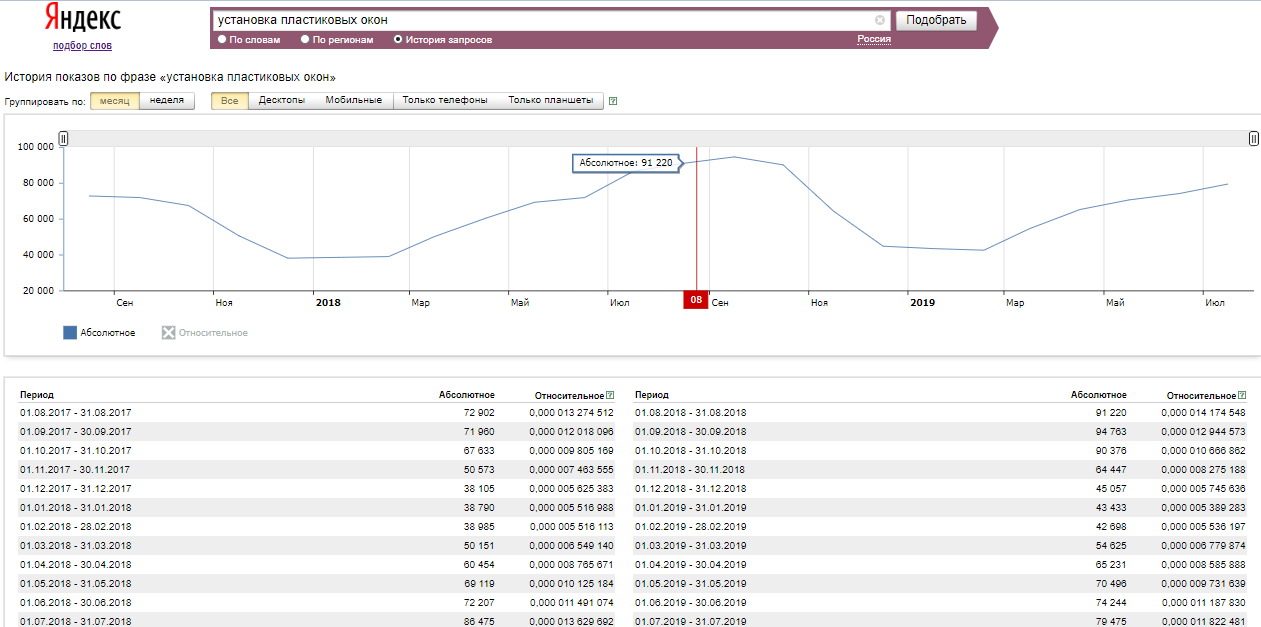
Вместе с этим можно заметить, что с марта идёт рост поисковых запросов, соответственно собирая данные в несезон, мы теряем часть запросов, по которым могут быть показы наших рекламных объявлений.
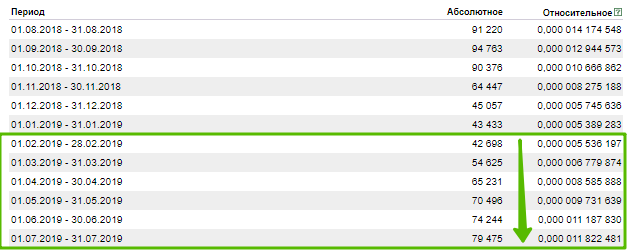
Итак: мы собрали РК в декабре, загрузили их в яндекс, запустили и решили дособрать семантику в августе с учетом новых данных. Нужно снова собрать все ключи и как-то исключить те, которые уже есть в наших рекламных кампаниях.
Для этого нам понадобились:
- маски, по которым мы собирали семантику;
- собранная семантика;
- любой парсер типа key collector или слово*б;
Маска – это вч (высокочастотный) ключ, по которому собираются все вложенные в него запросы. У нас это “установка пластиковых окон”.
Заходим в key collector или слово*б. Я заранее подготовил файл, по которому мы производили сбор зимой. Вы можете выгрузить семантику из интерфейса директа и загрузить в коллектор самостоятельно, далее распишу для чего...
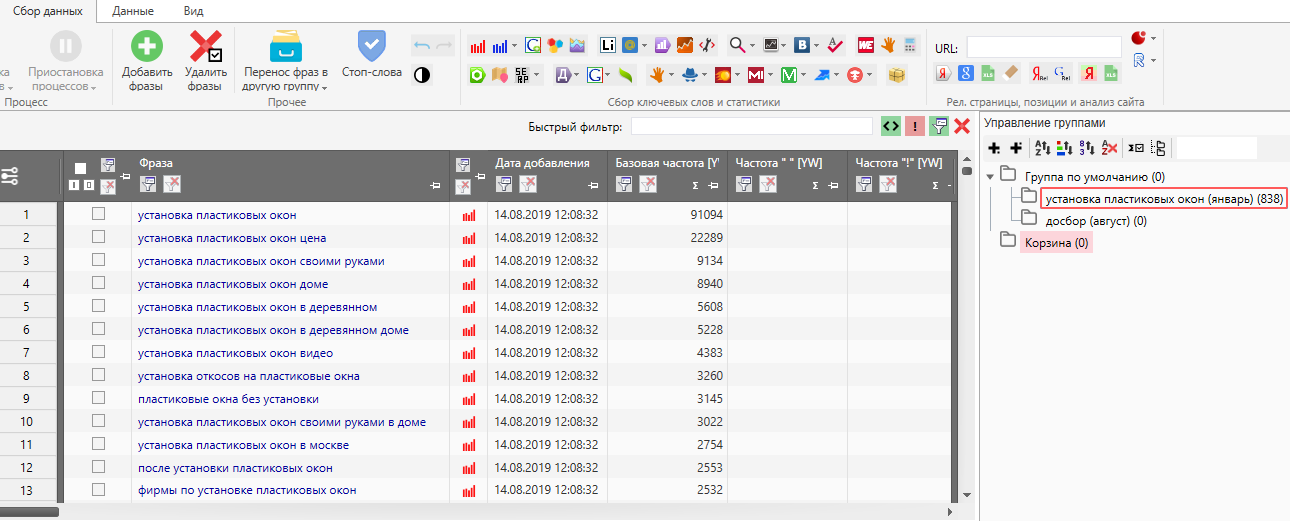
У нас получилось зимой порядка 800 ключей, далее выбираем папку досбор (август):
- Нажимаем пакетный сбор из левой колонки яндекса;
- Появляется окно настройки сборщика;
- Ставим галочку «не добавлять фразу, если она уже есть в любой другой группе;
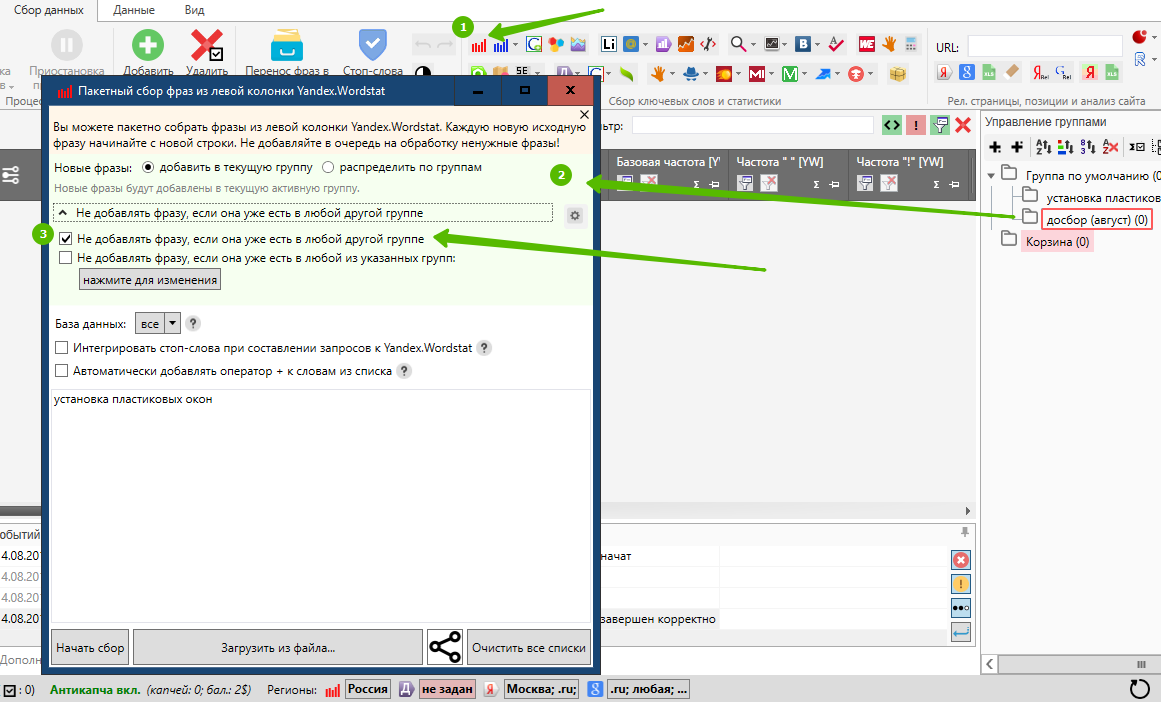
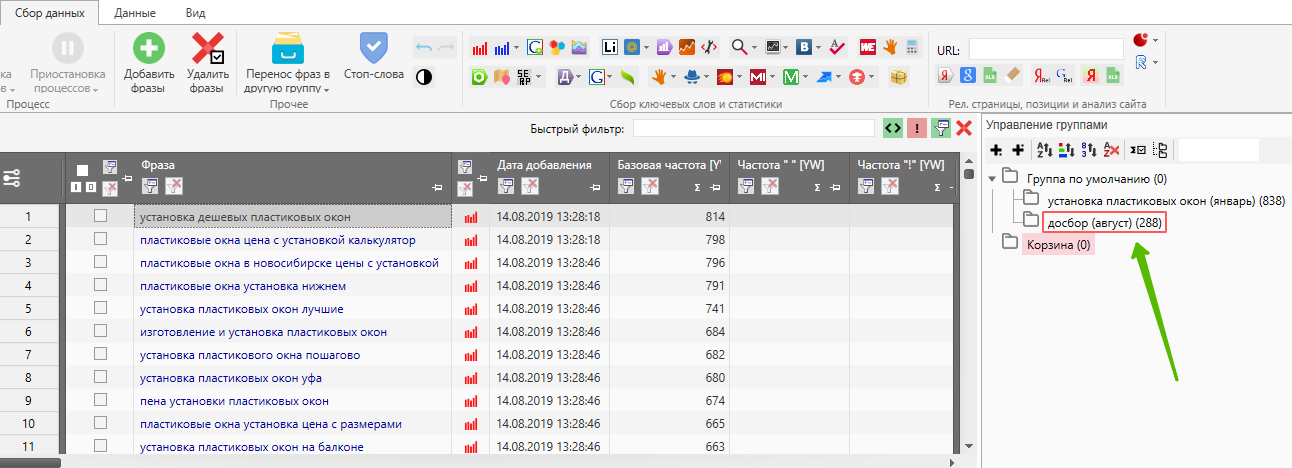
Итого мы собрали дополнительные 200 ключей, которые добавили к нашей РК.
Пишите комментарии, если будет много желающих-запишу видео – инструкцию, где всё еще раз подробнее разберем.
Вместе с этим мы разработали для сайта мини-квиз и добавили его на LP

Он показал очень хороший результат
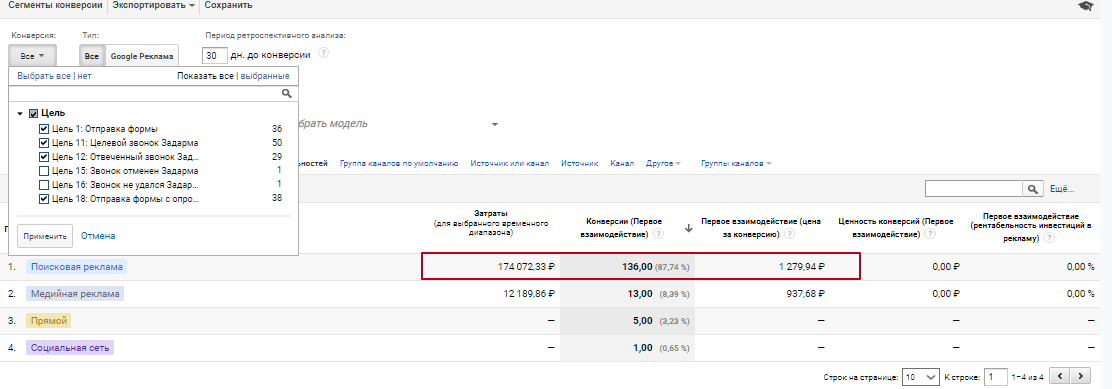
В итоге мы принесли в общем 136 лидов по цене 1200 руб.
Всем хороших лидов!
Подпишись и следи за выходом новых статей в нашем монстрограмме
Остались вопросы?
Не нашли ответ на интересующий Вас вопрос? Или не нашли интересующую Вас статью? Задавайте в комментариях вопросы и темы статей, которые Вас интересуют.









Комментарии
Статья очень интересная, но есть нюанс. Когда мы первый раз собрали семантику в декабре , то скорее всего вычистили из нее все минус слова и минус фразы. Когда мы загружаем этот список для досбора ключей, то он не включает в себя мусор. В результате парсер соберет как нужные запросы так и снова соберет весь мусор. Таким образом список придется заново чистить — а это занимает как минимум 30% времени работы с семантикой. Буду Вам очень благодарен , если вы напишите способ, который позволит избежать повторной чистки запросов.
Достаточно во время первой чистки семантики не удалять мусорные ключи, а перемещать их в другую папку (например, «корзина»). В этом случае, когда запустите парсинг спустя какое-то время, повторно такие же мусорные запросы не добавятся и объем работы сократится.
Это цена «чистых» лидов? Что за оконная компания?
Сложные вопросы от вас, Георгий. Затерялись статистически верные данные по этому материалу(
Может обсудим более свежую статью? Как насчет Tag Manager https://convertmonster.ru/blog/google-analytics-blog/chek-list-nastrojki-google-tag-manager/?
Вы можете выгрузить семантику из интерфейса директа и загрузить в коллектор самостоятельно. Как это сделать подскажите пожалуйста?
Есть 2 способа:
1. Выгрузка XLS/XLSX внизу интерфейса. Выгружается кампания и ключи в разных колонках.
2. Утилитой через рекламный аккаунт, копи-паст.