 Типичный сбор семантического ядра начинается с парсинга Wordstat или сбора ключевиков со всевозможных сервисов в KeyCollector. Затем наступает черед ручной кластеризации в Excel или KeyCollector. Весь процесс отнимает дюжину времени, а именно порядка 16–24 человекочасов seo-специалиста. Можно ли ускорить этот процесс без потери качества? Да, и мы расскажем, как это сделать.
Типичный сбор семантического ядра начинается с парсинга Wordstat или сбора ключевиков со всевозможных сервисов в KeyCollector. Затем наступает черед ручной кластеризации в Excel или KeyCollector. Весь процесс отнимает дюжину времени, а именно порядка 16–24 человекочасов seo-специалиста. Можно ли ускорить этот процесс без потери качества? Да, и мы расскажем, как это сделать.
Этап 1. Подготовительный
Шаг 1. Забыть про сбор максимального полного семантического ядра через парсеры Wordstat или KeyCollector и тем более руками. Вам не нужно тратить время seo-специалиста напрасно. Подробнее — ниже.
Шаг 2. Создать черновую структуру сайта, отталкиваясь от которой собрать семантическое ядро и, собственно, структуру сайта. Для этого даем клиенту заполнить бриф. В нем он должен описать, чем занимается компания, какие проблемы решает будущих пользователей, кто конкуренты, основные группы товаров или ключевые услуги. Посмотрите шаблон полного брифа. Если же вы владелец сайта, то ответьте на такие же вопросы для структуризации мыслей.
Шаг 3. После изучения брифа устраиваем мозговой штурм и делаем список общих ключевых фраз, которые характеризуют бизнес. Главное не прерывать мыслительный поток и записывать все фразы, даже нелепые на первый взгляд. Например, у нас интернет-магазин по продаже ортопедических матрасов, стульев и подушек. Тогда короткий список определяющих фраз будет такой:
- ортопедические матрасы
- ортопедические подушки
- ортопедические кресла
- ортопедические стулья
- стулья для осанки
- анатомические подушки
- матрасы для спины
- подушки для стульев.
Каждая фраза из этого списка — высокочастотник в тематике и определяет только тип товара. Дальше нужно расширять семантическое ядро средне- и низкочастотниками, а затем кластеризовать (разбивать всю семантику на подкатегории). На этих этапах мы и сэкономим время с помощью автоматизации.
Этап 2. Автоматизация уровень новичок
Сбор семантики
Выгрузить семантику с последующей кластеризацией можно с помощью Serpstat, поэтому шаги по работе в сервисах покажем на его примере. Также для сбора семантического ядра можно использовать SEMrush.
Шаг 1. Поочередно вводим ключевые фразы в сервис, выбираем регион поиска, под которое будет продвигаться сайт, и экспортируем все фразы из инструмента “Подбор фраз”. Также если у вас заготовлен список стоп-слов, вы можете добавить его в фильтр “Ключевые слова — не содержит” через запятую и выгрузить уже “чистую” семантику.
Процесс сбора семантики по одной ключевой фразе занимает до 3 минут.
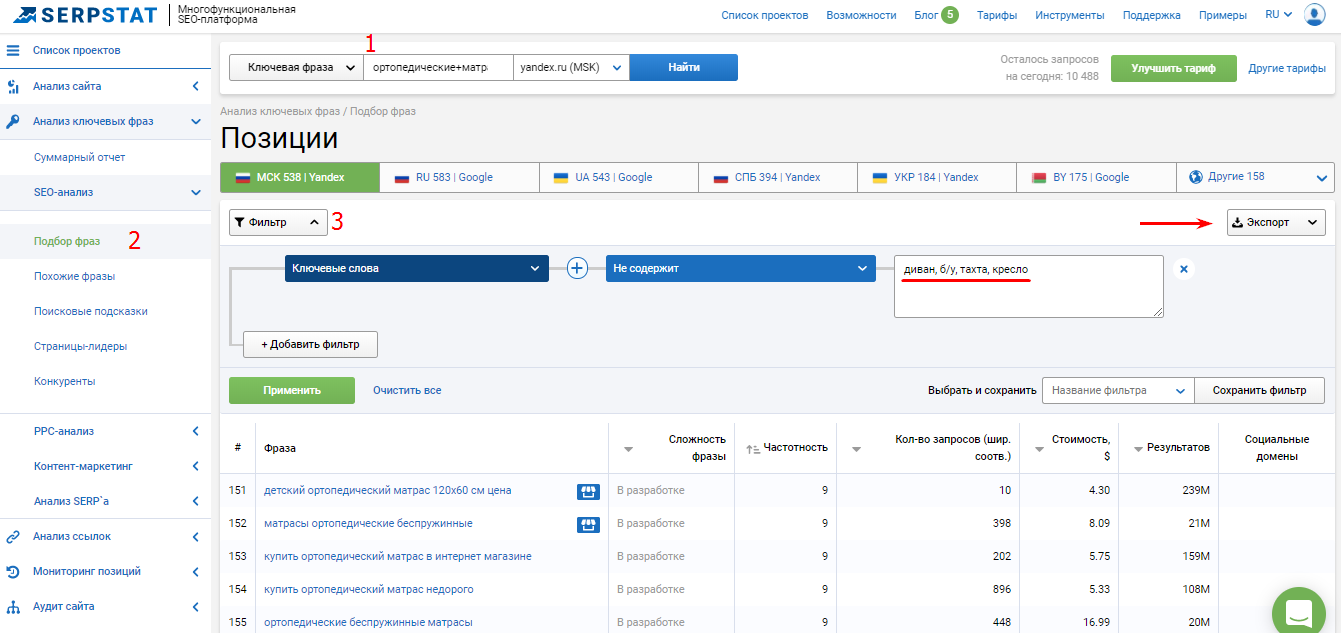 Шаг 2. Продолжаем расширять семантику, используя инструмент “Похожие фразы”, который находит синонимы фразы и сленговые выражения. Внедряя ключевики из этого отчета, вы максимально охватите запросы аудитории. А параметр “Сила связи” подскажет вам, используют ли эту фразу в своем семантическом ядре ваши конкуренты из топ-20. Чем выше число, тем больше сайтов используют исследуемую фразу и предложенный синоним.
Шаг 2. Продолжаем расширять семантику, используя инструмент “Похожие фразы”, который находит синонимы фразы и сленговые выражения. Внедряя ключевики из этого отчета, вы максимально охватите запросы аудитории. А параметр “Сила связи” подскажет вам, используют ли эту фразу в своем семантическом ядре ваши конкуренты из топ-20. Чем выше число, тем больше сайтов используют исследуемую фразу и предложенный синоним.
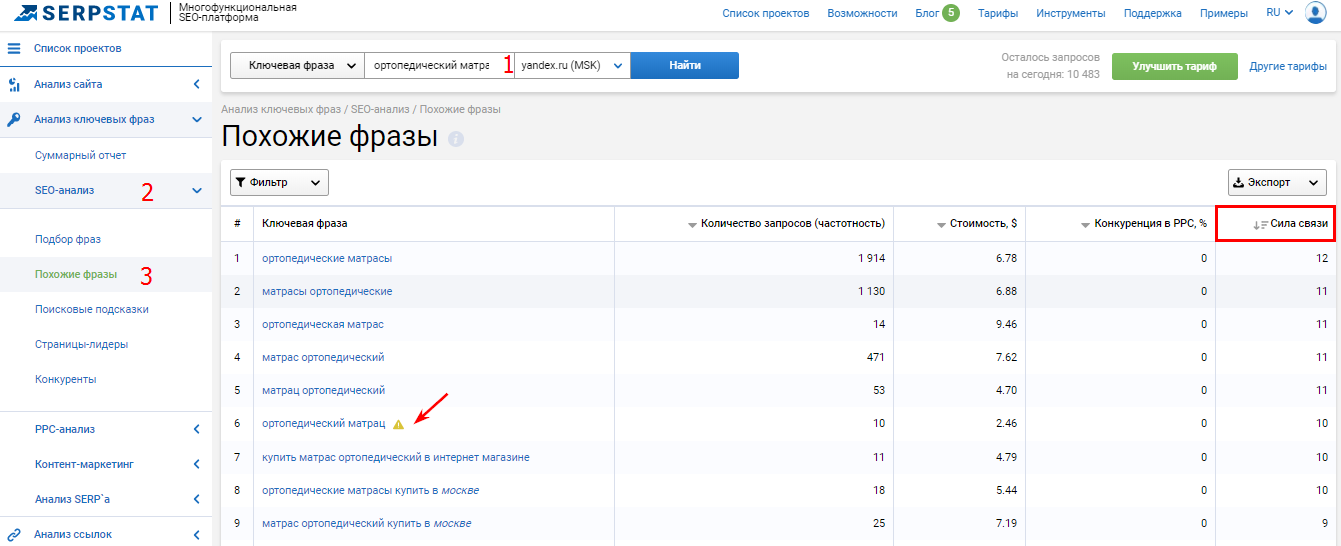 Выраженный результат показывается на товарах, которые люди могут искать по-всякому. Например, подушки для спины.
Выраженный результат показывается на товарах, которые люди могут искать по-всякому. Например, подушки для спины.
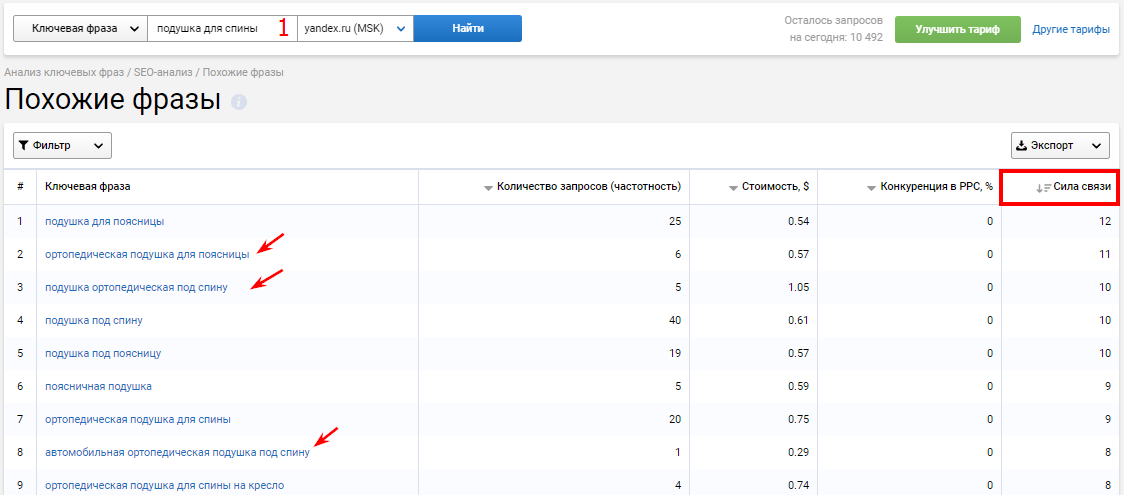 Шаг 3. Последний шаг в расширении семантики — это сбор поисковых подсказок поисковой системы. Преимущество в том, что сервисы собирают информацию в режиме реального времени и вытаскивают сразу все поисковые подсказки, которые может предложить Яндекс/Google. Поисковики же предлагают только до 12 подсказок на фразу.
Шаг 3. Последний шаг в расширении семантики — это сбор поисковых подсказок поисковой системы. Преимущество в том, что сервисы собирают информацию в режиме реального времени и вытаскивают сразу все поисковые подсказки, которые может предложить Яндекс/Google. Поисковики же предлагают только до 12 подсказок на фразу.
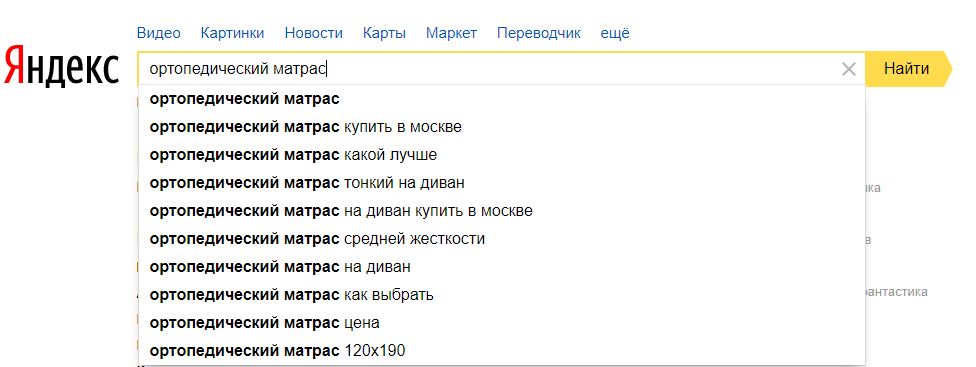
 Чтобы выгрузить все подсказки, переходим в инструмент “Поисковые подсказки” и выгружаем список.
Чтобы выгрузить все подсказки, переходим в инструмент “Поисковые подсказки” и выгружаем список.
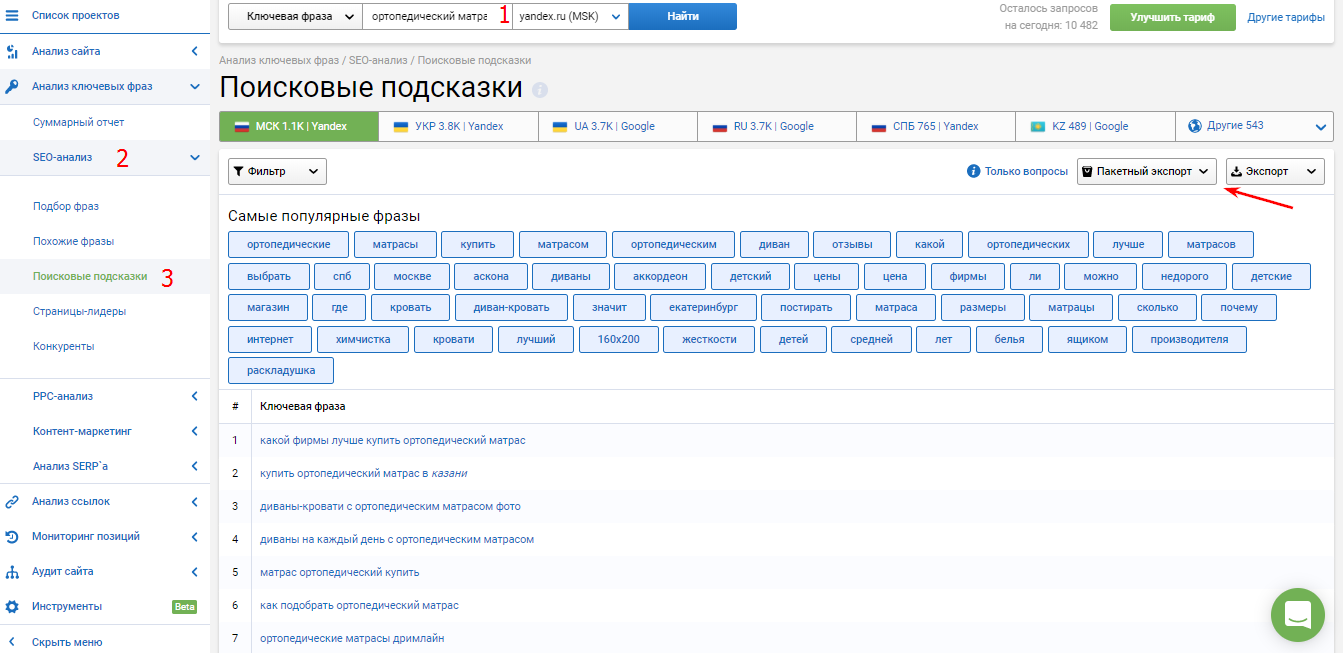 Обратите внимание на облако популярных фраз, именно такие слова чаще всего ищут люди со словосочетанием “ортопедические матрасы”. Если среди фраз есть определенные размеры, бренды или тип изделия, то стоит включить их в ассортимент интернет-магазина.
Также под информационный тип ключевиков, как “лучшие матрасы для проблем с позвоночником”, вы можете подготовить статью к вам в блог, что станет дополнительным источником трафика и продаж.
Шаг 4. Сводим все отчеты в единую таблицу и чистим дубли с помощью плагина Remove Duplicate.
Обратите внимание на облако популярных фраз, именно такие слова чаще всего ищут люди со словосочетанием “ортопедические матрасы”. Если среди фраз есть определенные размеры, бренды или тип изделия, то стоит включить их в ассортимент интернет-магазина.
Также под информационный тип ключевиков, как “лучшие матрасы для проблем с позвоночником”, вы можете подготовить статью к вам в блог, что станет дополнительным источником трафика и продаж.
Шаг 4. Сводим все отчеты в единую таблицу и чистим дубли с помощью плагина Remove Duplicate.
 Потраченное время — до 5 минут. Зависит от количества ключевых запросов.
Пользуюсь сервисами вы уже выигрываете время перед теми, кто собирает, чистит и кластеризует семантику вручную. Чтобы понять разницу, попробуйте провести все описанные шаги, вытаскивая ключевые фразы и поисковые подсказки в Wordstat, а затем повторите инструкцию.
Потраченное время — до 5 минут. Зависит от количества ключевых запросов.
Пользуюсь сервисами вы уже выигрываете время перед теми, кто собирает, чистит и кластеризует семантику вручную. Чтобы понять разницу, попробуйте провести все описанные шаги, вытаскивая ключевые фразы и поисковые подсказки в Wordstat, а затем повторите инструкцию.
Кластеризация
Также экономит до 8 часов автоматическая кластеризация. Это разбивка всех ключевых фраз на смысловые группы, под которые создается структура сайта, посадочные страницы, фильтры, категории товаров и так далее.
Для этого загрузите ваш файл со всеми ключевыми фразами в инструмент кластеризации и в течение 10–30 минут, в зависимости от количества ключевиков, вы получите отчет.
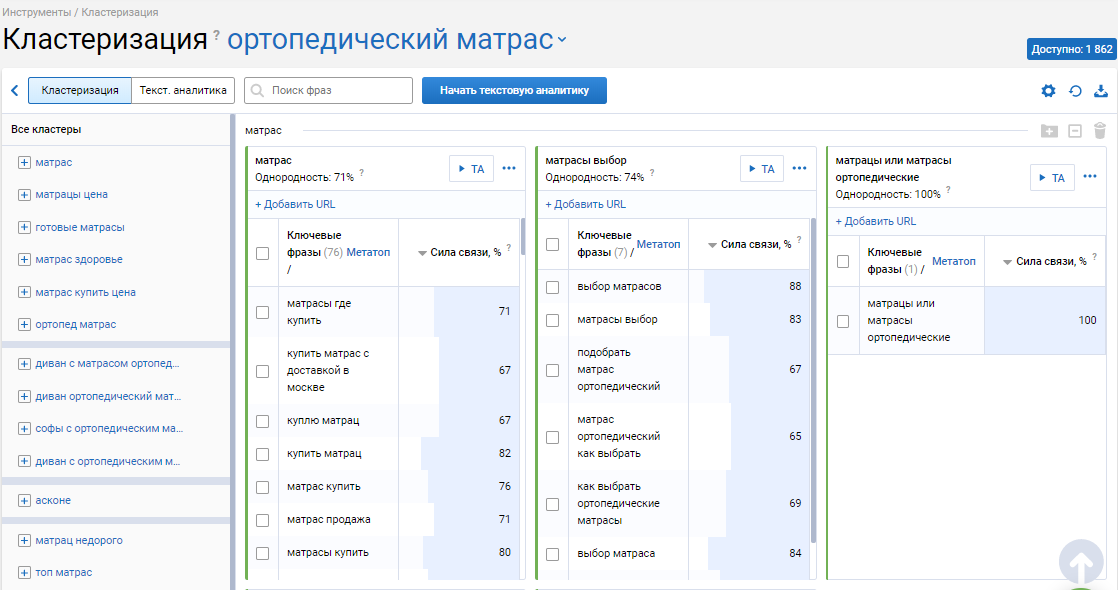 Если группировка не удовлетворяет качеством, не выходя из проекта, щелкните по значку “настройки” и поставьте силу связи сильнее/слабее. Изменение настроек в пределах одного проекта бесплатное, перегруппировка семантики длится не больше 1 минуты.
Если группировка не удовлетворяет качеством, не выходя из проекта, щелкните по значку “настройки” и поставьте силу связи сильнее/слабее. Изменение настроек в пределах одного проекта бесплатное, перегруппировка семантики длится не больше 1 минуты.
Этап 3. Автоматизация уровень профи
Если вы уже собираете семантику с помощью сервисов через интерфейс, пришло время познакомить вас с API. Это набор функций, позволяющих пользователям получать доступ к данным или компонентам сервиса, в нашем случае — Serpstat. Преимущество работы по API:
- Можете комбинировать разные отчеты в один, не заходя в сервис. При этом данные будут выгружаться со скоростью 10 запросов в секунду. Реально ли повторить такое руками? Конечно, нет 🙂
- Лимиты API (юниты) и лимиты в интерфейсе отличаются, по API вы получаете гораздо больше данных и дешевле. Даже если у вас закончились лимиты на сбор ключевых слов в интерфейсе, вы можете выгружать фразы, используя API.
- Вы можете не покупать подписку на сервис, а просто купить нужное вам количество API-юнитов и получать данные, не заходя в интерфейс.
- Можете написать любой скрипт для API и получать любые данные в один клик, которые не смогут добыть ваши конкуренты. Например, этот бесплатный скрипт ищет ветки форумов, которые ранжируются в топ-100 поисковой системы по тем же ключевым словам, что и ваш сайт. В результате вы получите список всех найденных URL-ов, их ключевые фразы, а также их позиции.
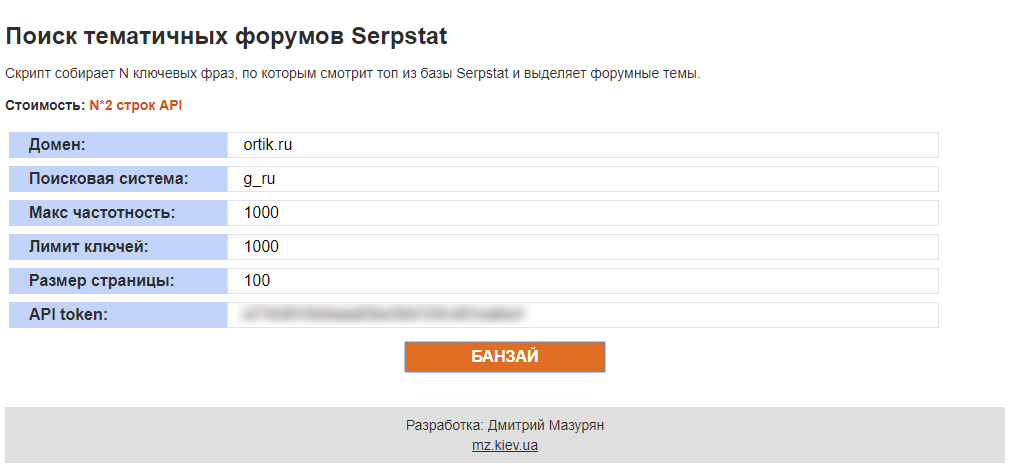
А теперь повторим все действия по сбору семантики со второго этапа с помощью API.
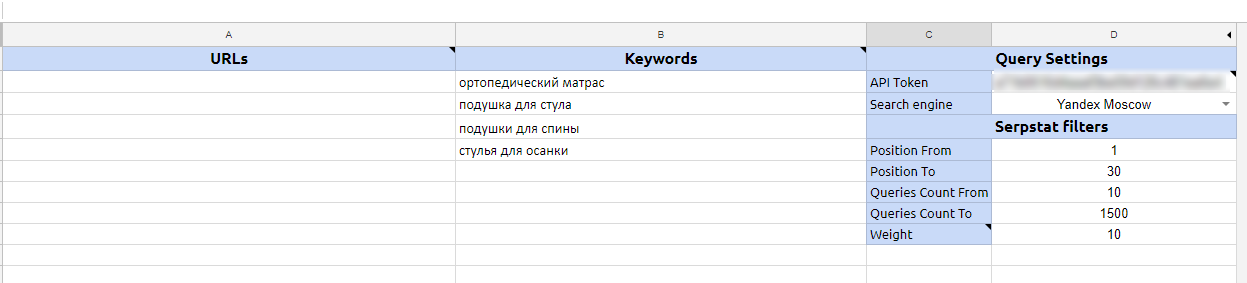
Шаг 1. Скопируйте эту таблицу со скриптом в свой Google Диск.
Шаг 2. Скопируйте свой токен в личном профиле Serpstat и вставьте в соответствующее поле в таблице. Также выберите нужную базу поисковика и заполните параметры отбора ключевых фраз, добавьте список ключевых фраз, по которым вы хотите выгрузить отчеты.
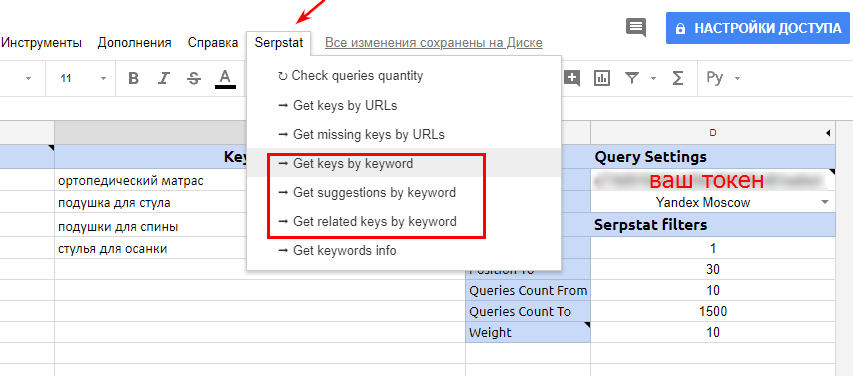
 Запустите скрипт, парся по очереди отчеты по подбору фраз, поисковых подсказок и похожих/сленговых фраз (см. скрин):
Запустите скрипт, парся по очереди отчеты по подбору фраз, поисковых подсказок и похожих/сленговых фраз (см. скрин):
 Программа попросит залогиниться через gmail-аккаунт и запросит доступ на разрешение работы. Подтвердите запуск скрипта, минуя предупреждение о небезопасности.
Шаг 3. Через 30–60 секунд скрипт завершит работу и соберет ключевые слова в рамках заданных параметров.
Программа попросит залогиниться через gmail-аккаунт и запросит доступ на разрешение работы. Подтвердите запуск скрипта, минуя предупреждение о небезопасности.
Шаг 3. Через 30–60 секунд скрипт завершит работу и соберет ключевые слова в рамках заданных параметров.
 Также в этом скрипте можно настроить фильтр по минус-словам и любые другие.
Итого мы сэкономили еще несколько часов работы seo-специалиста на сведении всех отчетов в один и сборе данных по каждому ключевому слову в интерфейсе.
Скрипты для работы по API могут писать ваши seo-специалисты, а можно найти официальные в открытом доступе.
Также в этом скрипте можно настроить фильтр по минус-словам и любые другие.
Итого мы сэкономили еще несколько часов работы seo-специалиста на сведении всех отчетов в один и сборе данных по каждому ключевому слову в интерфейсе.
Скрипты для работы по API могут писать ваши seo-специалисты, а можно найти официальные в открытом доступе.
Выводы
Максимально ускоряют сбор семантического ядра без потери качества такие действия:
- Кластеризация с помощью специальных сервисов.
- Парсинг ключевых слов, подсказок и сленговых выражений по API seo-платформ.
Помните, что ваши лидирующие конкуренты в лице других бизнесов или агентств по поисковому продвижению уже используют различные сервисы автоматизации и обгоняют сборщиков семантики руками на десять шагов. Поэтому осваивайте новые решения и будьте в топе! Начать можно с seo аудита:
Получить предложение!
Подпишись и следи за выходом новых статей в нашем
монстрограмме.
 28.04.2018
28.04.2018  8 616
8 616 








Комментарии
Спасибо, не сэкономил.
Нормально же общались, Артем….
Рекомендую протестировать KeyClusterer — бесплатная программа для кластеризации поисковых запросов методами Hard и Soft. При этом по набору функций практически не уступает платным аналогам.